Introduction
In January, I wrote a post called “Dynamic Linking Needs to Die”. As should be evident from the title, it was too inflammatory. And by “too inflammatory,” I mean that it was inflammatory at all.
Does dynamic linking need to die? Actually, no, I’m sure there’s a place for it somewhere. So just by that, that post was too inflammatory.
This post will attempt to fix that. It will also take into account new sources that I have found since. It will also directly address the arguments that the king of dynamic linking, Ulrich Drepper, made against static linking.
His article is called “Static Linking Considered Harmful”, and I consider it harmful. Unironically.
But to be clear, I also consider my original “Dynamic Linking Needs to Die” post exactly as harmful, for the same reason: it’s too strong. I say that dynamic linking should not exist, and Ulrich Drepper’s post comes to the same conclusion about static linking.
We are both wrong in the same way: we don’t allow for using the best tool for the job.
However, there is one big elephant in the room: right now, there are a lot of
platforms that do not fully support static linking because you have to
dynamically link libc or other system interfaces. The only one I know of that
supports static linking is Linux.
I think this is a shame, but it is also reality.
This means that a majority of this post will be Linux-centric, but there will be ideas in it for other platforms as well.
Also, wherever I run benchmarks in this post, they are being run on an x86_64
machine with an AMD Ryzen Threadripper 1900X, 32 GB ECC RAM, running an
up-to-date Gentoo Linux 5.10.10 under the amd64/17.1/desktop profile.
Drepper’s Arguments
Now, before I start, I have a confession: my arguments may be straw man arguments.
Ulrich Drepper wrote his article sometime during or before November 2006. This means that some of his arguments will be outdated. I will try to clarify which arguments are out-of-date, but I will, in essence, be arguing against a straw man.
Nevertheless, let’s go through his post, point-by-point, in the order he gave them.
Security Fixes
Ulrich Drepper claims, rightly, that you only need to update a shared library to apply security fixes to all executables that rely on that library.
This is a good thing! It is also a good vision.
Unfortunately, it is only a vision because it’s not the whole story.
As of yet, there is no way to automatically determine if the ABI or API of a shared library changed between updates. This is called DLL Hell.
To make it worse, changing either ABI or API can introduce security vulnerabilities too.
This is a specific example of an ABI break causing problems.
Such security vulnerabilities would be doubly insidious because they would be hidden; they would never show up with an audit of just the source code of the library and its dependent.
Specifically, you need to at least audit the differences between the original and the update as well.
I don’t think Ulrich Drepper could have foreseen all of the problems with DLL Hell (though there were signs on Windows), but in retrospect, such problems make the argument moot because to ensure that no problems crop up when updating a shared library, you would probably want to recompile all of its dependents anyway!
And that is without even mentioning the problems and complexity of symbol versioning, a problem so complex that it hasn’t even been solved!
On top of that, the solutions for symbol versioning are so bad that Linus Torvalds said, “almost no shared libraries are actually version-safe,” which to me, means that it’s unworkable for developers to use, since developers are the users of symbol versioning.
However, to be fair to shared libraries, static libraries have no advantage here because there is no easy way to update executables that use static libraries either.
Personally, I think a redesign is needed, and I will give some ideas later in this post.
Security Measures
Next, Ulrich Drepper says that static linking cannot use security measures like Address Space Layout Randomization (ASLR).
This was true back when he wrote his article, so this will be a straw man argument, to a point.
Anyway, nowadays, we have static PIE, which allows ASLR in static binaries. Cool. So that’s not an argument that I need to defeat.
Except that I think that Ulrich Drepper’s article was harmful for another reason: it distracted us (meaning “us” as an industry) from a better solution to security problems than ASLR: separating the code and data stacks, which I talk about below.
Efficient Use of Physical Memory
Ulrich Drepper claims that shared libraries provide:
more efficient use of physical memory. All processes share the same physical pages for the code in the DSOs.
Drew DeVault already measured the amount of sharing of shared libraries, so I’m going to shamelessly steal his code.
These numbers only directly measure sharing on disk, but I’ll show how it applies to RAM later.
First, libs.awk:
/\t.*\.so.*/ {
n=split($1, p, "/")
split(p[n], l, ".")
lib=l[1]
if (libs[lib] == "") {
libs[lib] = 0
}
libs[lib] += 1
}
END {
for (lib in libs) {
print libs[lib] "\t" lib
}
}
Then, I ran these commands:
$ find /usr/bin -type f -executable -print \
| xargs ldd 2>/dev/null \
| awk -f libs.awk > results.txt
$ find /usr/local/bin -type f -executable -print \
| xargs ldd 2>/dev/null \
| awk -f libs.awk >> results.txt
$ find /usr/sbin -type f -executable -print \
| xargs ldd 2>/dev/null \
| awk -f libs.awk >> results.txt
$ find /sbin -type f -executable -print \
| xargs ldd 2>/dev/null \
| awk -f libs.awk >> results.txt
$ find /bin -type f -executable -print \
| xargs ldd 2>/dev/null \
| awk -f libs.awk >> results.txt
$ cat results.txt | sort -rn > fresults.txt
$ awk '{ print NR "\t" $1 }' < fresults.txt > nresults.txt
$ gnuplot
gnuplot> plot 'nresults.txt'
gnuplot> quit
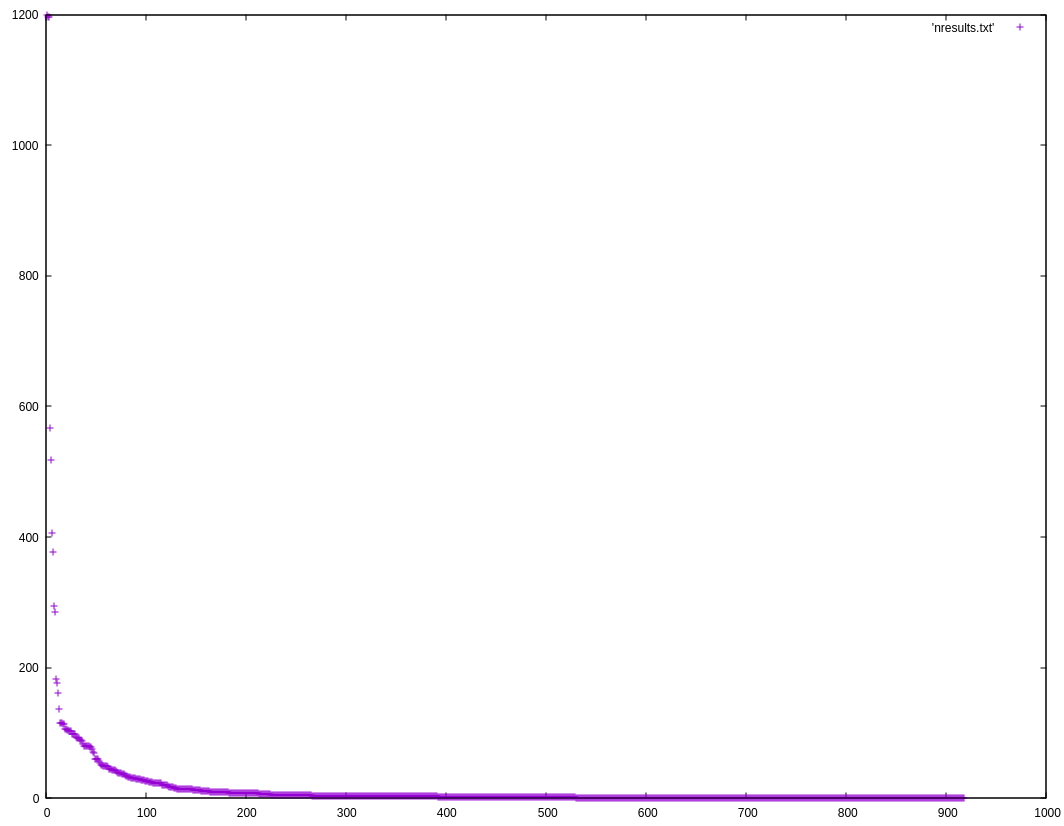
There are a lot of users of a few libraries, so let’s see which libraries are used most.
$ find /usr/bin -type f -executable -print > nexecs.txt
$ find /usr/local/bin -type f -executable -print >> nexecs.txt
$ find /usr/sbin -type f -executable -print >> nexecs.txt
$ find /sbin -type f -executable -print >> nexecs.txt
$ find /bin -type f -executable -print >> nexecs.txt
$ cat nexecs.txt | wc -l
1982
$ cat nresults.txt | wc -l
918
$ head -n20 fresults.txt
1199 libc
1197 linux-vdso
1197 ld-linux-x86-64
567 libm
518 libpthread
407 libdl
377 libz
294 libgcc_s
285 libstdc++
183 libpcre
176 libglib-2
162 libbz2
137 libpng16
116 libgraphite2
115 libharfbuzz
115 libfreetype
114 libicuuc
114 libicudata
106 libmd
106 libbsd
Drew DeVault also measured how much of the libraries were used (by number of symbols), so let’s do that too, using his code.
First, nsyms.go:
package main
import (
"bufio"
"fmt"
"os"
"os/exec"
"path/filepath"
"strings"
)
func main() {
ldd := exec.Command("ldd", os.Args[1])
rc, err := ldd.StdoutPipe()
if err != nil {
panic(err)
}
ldd.Start()
var libpaths []string
scan := bufio.NewScanner(rc)
for scan.Scan() {
line := scan.Text()[1:] /* \t */
sp := strings.Split(line, " ")
var lib string
if strings.Contains(line, "=>") {
lib = sp[2]
} else {
lib = sp[0]
}
if !filepath.IsAbs(lib) {
lib = "/usr/lib/" + lib
}
libpaths = append(libpaths, lib)
}
ldd.Wait()
rc.Close()
syms := make(map[string]interface{})
for _, path := range libpaths {
objdump := exec.Command("objdump", "-T", path)
rc, err := objdump.StdoutPipe()
if err != nil {
panic(err)
}
objdump.Start()
scan := bufio.NewScanner(rc)
for i := 0; scan.Scan(); i++ {
if i < 4 {
continue
}
line := scan.Text()
sp := strings.Split(line, " ")
if len(sp) < 5 {
continue
}
sym := sp[len(sp)-1]
syms[sym] = nil
}
objdump.Wait()
rc.Close()
}
objdump := exec.Command("objdump", "-R", os.Args[1])
rc, err = objdump.StdoutPipe()
if err != nil {
panic(err)
}
objdump.Start()
used := make(map[string]interface{})
scan = bufio.NewScanner(rc)
for i := 0; scan.Scan(); i++ {
if i < 5 {
continue
}
sp := strings.Split(scan.Text(), " ")
if len(sp) < 3 {
continue
}
sym := sp[len(sp)-1]
used[sym] = nil
}
objdump.Wait()
rc.Close()
if len(syms) != 0 && len(used) != 0 && len(used) <= len(syms) {
fmt.Printf("%50s\t%d\t%d\t%f\n", os.Args[1], len(syms), len(used),
float64(len(used)) / float64(len(syms)))
}
}
Second, I used these commands:
$ go build nsyms.go
$ find /usr/bin -type f -executable -print | xargs -n1 ./nsyms > syms.txt
$ find /usr/local/bin -type f -executable -print | xargs -n1 ./nsyms >> syms.txt
$ find /usr/sbin -type f -executable -print | xargs -n1 ./nsyms >> syms.txt
$ find /sbin -type f -executable -print | xargs -n1 ./nsyms >> syms.txt
$ find /bin -type f -executable -print | xargs -n1 ./nsyms >> syms.txt
$ awk '{ n += $4 } END { print n / NR }' < syms.txt
0.060664
$ awk '{ print $4 }' < syms.txt > usyms.txt
So on average, executables use about 6% of the symbols in shared libraries on my machine.
$ gnuplot
gnuplot> set yrange [0:1]
gnuplot> set border 2
gnuplot> set style data boxplot
gnuplot> set boxwidth 0.5 absolute
gnuplot> set pointsize 0.5
gnuplot> set style fill solid 0.5 border -1
gnuplot> plot 'usyms.txt' using (1):1
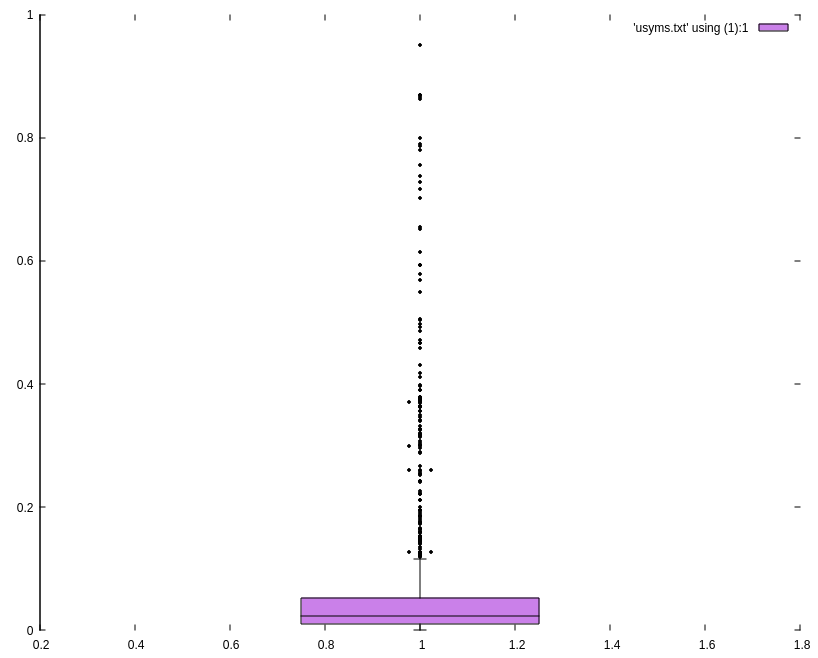
If we could assume that programs would use as many different symbols as possible, then it would take:
$ bc -lq
>>> 1/0.060664
16.48424106554134247659
>>> quit
around 16 programs using the same library to break even on disk space.
$ cat fresults.txt | awk '$1 > 16' | wc -l
127
$ cat fresults.txt | wc -l
918
$ bc -lq
>>> 127/918
.13834422657952069716
>>> quit
So I have 127 of 918 libraries (13.8%) that are more efficient on disk than using static libraries.
But in order to figure out if shared libraries are more efficient at using RAM, we need to estimate how many of those programs going to use the same symbols as each other.
I don’t want to do the math, but knowing the principles behind the Birthday Problem should allow us to estimate.
In this case, I’m going to estimate that no more than 3 or 4 users of a library are needed in order to break even. There are a few reasons:
- Operating systems will not map pages of shared libraries in that are not used.
- The Birthday Problem shows that the eventuality of a collision is 50% at about the square root of the number at play. In this case, we’ll use 16 as the number, and its square root is 4.
The math above is really spitballing because I really should be calculating it per library based on how many symbols the library has, but I am too lazy. However, it is low enough that I think it’s fair to shared libraries.
So how many libraries on my system have at least 4 users?
$ cat fresults.txt | awk '$1 >= 4' | wc -l
304
$ cat fresults.txt | wc -l
918
$ bc -lq
>>> 304/918
.33115468409586056644
>>> quit
So just under a third of my shared libraries do result in more efficient RAM use.
This means that this argument could still be valid, to a point. Drepper may still be right about this, mostly for libraries with a lot of users.
My bc library does not have a lot of users, so I’ll keep distributing
it as a static library.
Of course, users should be able to decide for themselves whether that tradeoff is worth it. Personally, I prefer better security; I’ll take the extra RAM use.
Startup Times
Ulrich Drepper also said:
With prelinking startup times for dynamically linked code is as good as that of statically linked code.
Let’s see how true that is.
Edit (2021-10-03): I have been made aware that prelinking is not done automatically, as I thought, so the numbers below do not refute Drepper’s point.
The code I am using also comes from Drew DeVault’s “Dynamic Linking” post,
and I am using musl 1.2.2 (installed at /usr/local/musl) and GCC 10.3.0.
First, ex.c:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
fprintf(stdout, "%ld\t", ts.tv_nsec);
fflush(stdout);
if (argc == 1) {
char *args[] = { "", "", NULL };
execvp(argv[0], args);
} else {
fprintf(stdout, "\n");
}
return 0;
}
Then, test.sh:
#!/bin/sh
i=0
while [ $i -lt 1000 ]
do
./ex
i=$((i+1))
done
Finally, my results:
$ /usr/local/musl/bin/musl-gcc -o ex ex.c
$ ./test.sh | awk 'BEGIN { sum = 0 } { sum += $2-$1 } END { print sum / NR }'
102430
$ /usr/local/musl/bin/musl-gcc -static -o ex ex.c
$ ./test.sh | awk 'BEGIN { sum = 0 } { sum += $2-$1 } END { print sum / NR }'
52566.1
So my results coincide (roughly) with what Drew got, ratio-wise. And now there are two examples of Drepper being wrong on startup times.
To be honest, startup times probably do not matter much, unless you are launching a lot of processes all the time, such as in shell scripts.
Features of libc
Ulrich Drepper says:
all kinds of features in the libc (locale (through iconv), NSS, IDN, …) require dynamic linking to load the appropriate external code. We have very limited support for doing this in statically linked code. But it requires that the dynamically loaded modules available at runtime must come from the same glibc version as the code linked into the application. And it is completely unsupported to dynamically load DSOs this way which are not part of glibc. Shipping all the dependencies goes completely against the advantage of static linking people site: that shipping one binary is enough to make it work everywhere.
First, locale does not need to happen through iconv; my bc uses POSIX
catalogs.
Second, iconv can be statically linked, so at least for that feature, Drepper’s argument is moot.
For NSS, there is an implementation that can be statically linked.
For IDN, it is probably like iconv, but I am not entirely sure.
Last of all, I want to address something specific Drepper said:
We have very limited support for doing this in statically linked code.
To me, this sounds like Drepper is saying that these features require dynamic
linking not because of any inherent limitations of static linking, but that
glibc has decided to implement them in such a way that they do not have to
support static linking.
If true, this is not a good argument against static linking. It’s like King Candy’s argument that Vanellope should not race: it sounds right, to protect Vanellope, except that King Candy himself created the situation that made Vanellope need protection because that situation was better for King Candy.
In this case, Drepper himself created the situation where dynamic linking was necessary and then used that as an argument that dynamic linking is the only option.
That doesn’t mean dynamic linking is better for developers; it means that dynamic linking is better for Ulrich Drepper.
He also says:
Related, trivial NSS modules can be used from statically linked apps directly. If they require extensive dependencies (like the LDAP NSS module, not part of glibc proper) this will likely not work. And since the selection of the NSS modules is up the the person deploying the code (not the developer), it is not possible to make the assumption that these kind of modules are not used.
(Emphasis added.)
So he admits that static linking can be done. He also admits that the selection of modules is under the control of the system administrator. If the system administrator wants to statically link those modules because he knows his systems, he should be able to.
In other words, Drepper’s argument that static linking hinders access to
features of libc is dishonest because it does not have to, as musl shows.
Thus, I claim that this argument is moot.
No Accidental Violation of the (L)GPL
Ulrich Drepper’s next argument is that dynamic linking prevents accidental violation of the GPL and LGPL.
This may be true for the LGPL, but for the GPL, "[t]he jury is still out on this one."
But to me, this just sounds like an argument against the virality of the GPL, not static linking, and I have posted my thoughts about the virality of the GPL elsewhere.
So, I guess I concede that this is an actual, current advantage of dynamic linking, but only for the LGPL. And I avoid LGPL code anyway.
While I do not like the GPL family of licenses, I have nothing against many of the people of the FSF. In fact, in a recent email conversation, one of the staff at the FSF was extraordinarily friendly to me, despite knowing my stance on the GPL family. That I can respect.
Debugging and Profiling Is Harder
Next, Ulrich Drepper claims that static linking makes debugging and profiling harder.
He mentions four “tools and hacks” that static linking makes impossible:
ltraceLD_PRELOADLD_PROFILELD_AUDIT
I will address each of these in turn.
ltrace, according to its manpage, is a program like strace, except
that instead of just tracing system calls, it traces dynamic library calls and
signals received.
The truth is that you could do this with a proper build of a static library that tracked calls for you. In fact, that would give you more control because you could pick and choose which functions to trace at a fine-grained level.
Edit (2021-10-03): I have been informed that ltrace lets you do this as
well.
And for signals? Write an intermediary function to register signal handlers, and then have signal handler that handles all signals and passes them to the real signal handlers. Not hard, and it does not need an outside binary.
LD_PRELOAD is meant to load shared libraries before libc. This does
allow cool things like replacing the malloc() implementation. But again, you
can do this by rebuilding with static libraries.
And that is not even talking about the fact that LD_PRELOAD has been used for
injection attacks!
LD_PROFILE lets you profile shared libraries. This is not even needed if
you use static linking.
LD_AUDIT allows you to audit dynamic linking events. This is not even
needed if you use static linking.
Opaque Libraries
However, and this is a BIG “however”: all of my arguments against these techniques assume that you can build the relevant code from source. If you can’t, and you need to profile, audit, or otherwise debug an opaque library or executable, then static linking cannot help you much.
But to me, that sounds more like an argument for open source than an argument against static linking. Why? Because if you don’t have the source, how can you change the library or executable anyway?
Sometimes, you won’t need to because you just need to reverse engineer its behavior. But when you need to, an opaque library or executable is just a liability.
And in addition to all of the above, I believe that opaque libraries and executables are a security vulnerability themselves. The reason is because opaque libraries and executables can be updated without audits. This means that security vulnerabilities can be introduced without being caught. Not updating them is also not good because they will probably have existing security vulnerabilities.
Thus, opaque libraries and executables have, and are, potential security vulnerabilities both if they are updated and if they are not.
In turn, this means that if you have opaque shared libraries, debugging, profiling, and auditing them are going to do you little good.
And I did not even mention LD_LIBRARY_PATH, which adds yet more complexity and
can be yet another attack vector.
Trusting Users
Ulrich Drepper also adds:
These can be effective debugging and profiling, especially for remote debugging where the user cannot be trusted with doing complex debugging work.
What does he mean when he said, “when the user cannot be trusted with doing complex debugging work”?
I understand that there are some unintelligent users out there, but that sounds eerily similar to Apple’s and Microsoft’s claims that they need to lock down their hardware and software to protect users from themselves.
At this point, we know that argument was a straw man: Apple and Microsoft did it not for users, but for themselves.
Likewise, while Ulrich Drepper’s intentions may have been good, I have a hard time believing that they were, simply because his arguments sound so uncannily like ones used to take advantage of others and because one of his previous arguments was based on what was best for himself.
Disadvantages of Shared Libraries
Now that I have directly answered Ulrich Drepper’s arguments, I want to address the disadvantages of dynamic linking, in the order from most important to least important (in my opinion).
Complexity and Security Problems
It is obvious that there is more complexity behind dynamic linking, but have you really thought about how much complexity there is behind dynamic linking?
First, read this blog post series on linkers.
Then realize that the dynamic linker itself has to be statically-linked because if it isn’t, who will link the linker?
This is a big reason that arguments for dynamic linking feel disingenous to me: the implementers of dynamic linking get static linking, but they don’t want you to have it. It feels like another instance of “rules for thee, but not for me.”
Then realize that the operating system is basically executing code you don’t control when you run a program you wrote.
Then realize that all of this actually makes the operating system, the most important thing, much more complicated!
Then remember that all of that complexity happens at not at build time, the best time to solve problems, but at startup time, when problems are harder to solve and when you can least afford problems cropping up.
Of all of these things, some still apply to static linking. For example, most of the information in the linker series still applies, except for the runtime linking. However, these still only apply at build time, when you have most control over it.
But running the runtime linker and making the OS more complex do not apply.
This complexity might be justifiable if any of Drepper’s arguments carried any weight. But they do not.
Actually, the complexity would be justifiable only if the arguments that focus on security carried any weight because complexity breeds bugs, and bugs breed security vulnerabilities. In other words, complexity breeds insecurity.
Let me repeat that again: complexity breeds insecurity.
And this already applies to dynamic linking since the dynamic linker can have bugs. In fact, there already were three big ones.
First, the linker can sometimes map segments containing const data into
writeable memory, allowing attackers to overwrite constant data.
Second, ldd can be manipulated into executing arbitrary code.
Third, FreeBSD’s mechanism for ignoring LD_PRELOAD for SUID/SGID binaries used
to have a bug that allowed it to be bypassed.
In my opinion, these issues mean that Drepper’s security arguments are moot because the dynamic linker itself is a security problem.
No Reproducible Builds
In my opinion, this is, by far, the biggest reason to use static libraries. It’s so important, I put a link in the section header to a website that is all about reproducible builds.
To be honest, if I cannot convince you of the utility of reproducible builds, then I can’t convince you of anything.
Please do check out the materials in the reproducible builds website. It’s all great, and even if you cannot get fully reproduced builds, you can probably use the techniques to eliminate a lot of differences between builds and better reproducibility of bugs across builds.
I believe that reproducible builds are important because I am in the process of designing a build system.
Yes, I know (language warning).
This build system is because I need a cross-platform one, and CMake doesn’t fulfill my needs.
I think reproducible builds are something to build into the design from the start, even if it is not possible to support them in the first version, so I have done a lot of thinking about what they would require.
This is a small list of what they require:
- Exact same config,
- used to do a clean build,
- with the exact same compiler(s),
- which means the compiler(s) need(s) a reproducible build too.
To get the exact same compiler, you would need to make sure that you can bundle its required shared libraries with it and shim them in when running it on another machine. Good luck with that, especially since you may actually need to bundle in the dynamic linker too!
With a statically-linked compiler? Easy! The only requirement for it is that the OS version supports the exact same syscalls that the compiler needs. Just bundle the compiler, and one major obstacle to reproducible builds is gone.
In fact, I think I would go so far as to say that reproducible builds are nigh impossible, if not actually impossible, in the presence of dynamic linking.
Unfortunately, as I noted above, only Linux supports static linking.
However, I do hope that statically linking everything but the system libraries will not cause problems with reproducible builds on other platforms.
The sad thing is that it’s still only a hope, not a guarantee.
ABI Breaks Impede Progress
This is a new disadvantage that I discovered recently by reading a blog post that, like “What Color Is Your Function?” by Bob Nystrom, will become a Computer Science classic.
That blog post is “Binary Banshees and Digital Demons” by JeanHeyd Meneide.
Its tl;dr is that the C and C++ committees are so committed to not breaking the ABI that it actually impedes the progress of those two languages and also leads to bad design decisions.
In other words, the fear of ABI incompatibility actually holds C and C++ back.
This is worrying to me because I’m designing a language. I do not want my language to be held back because of ABI concerns.
Well, it doesn’t have to be: I could just declare that its standard library will be statically-linked by default and if people want to use dynamic linking, they need to be aware of ABI breaks.
Why does static linking solve the problem? Because static linking prevents code from being silently updated behind a program’s back. When it runs, it knows that the static libraries it uses still have the same ABI. And when the static libraries are updated, it’s at build time when ABI breaks (and API breaks) are easily caught by the compiler and linker, or are a non-issue at build time.
Syscall ABI’s vs ABI’s
Earlier, I noted that most operating systems, besides Linux, require you to dynamically link their system libraries because they don’t want to support a stable syscall ABI.
The ironic thing is that operating systems only supported a stable syscall ABI, rather than requiring programs to dynamically link system libraries, they would have less problems with ABI breaks.
The argument against that is that they don’t want to guarantee system call numbers. However, if they need to change any syscalls, they could just add a new one with the desired behavior and deprecate the old one.
Then, if they needed to deprecate old system calls, it would be a simple matter
to direct those old system calls to a function that does the equivalent of a
SIGKILL after a period of deprecation.
Non-Transferable Binaries
Because only Linux supports static linking, this “advantage” of static linking is only applicable on Linux.
With a statically-linked binary, you can copy it to another machine with a Linux that supports all of the needed syscalls, and it will just run.
If you want to do that with a dynamically linked executable, you have to do exactly what I mentioned above. In fact, this fact about dynamically-linked binaries is one reason why they are such an obstacle to reproducible builds.
And default statically-linked binaries is one of the reasons the Go language became popular. I don’t think that’s a coincidence.
Performance
I have a confession: I’m not sure performance is an advantage for either static or dynamic libraries. The reason is that performance is affected by many factors, and all factors matter.
I can cherry pick examples, but as far as I can tell, the general gist is that individual programs run better with static linking, but the system as a whole might run better using dynamic linking with heavy sharing.
But I am arguing for static linking, so I want to mention how it makes individual programs run faster:
- Lower startup times.
- Better optimization opportunities, especially using link-time optimization.
- Less function call overhead.
Benchmarks
I want to run some benchmarks!
I ran the following commands in the root directory of my bc at commit
317169bfdb:
$ CC=/usr/local/musl/bin/musl-gcc CFLAGS="-flto" ./configure -O3
[snip...]
$ make
[snip...]
$ ./scripts/benchmark.sh -n20 bc add bitfuncs constants divide lib multiply \
strings subtract > ../bench1.txt
$ CC=/usr/local/musl/bin/musl-gcc CFLAGS="-static -flto" ./configure -O3
[snip...]
$ make
[snip...]
$ ./scripts/benchmark.sh -n20 bc add bitfuncs constants divide lib multiply \
strings subtract > ../bench2.txt
$ make ministat
[snip...]
$ ./scripts/ministat -w78 -C1 -c99.5 ../bench1.txt ../bench2.txt
x ../bench1.txt
+ ../bench2.txt
+------------------------------------------------------------------------------+
| + |
| ++ |
| +++ |
| + *++ x x |
|x x + ++ + * **+ **x x xxx x x xx x|
| |___AM__|________MA_________________| |
+------------------------------------------------------------------------------+
N Min Max Median Avg Stddev
x 20 18.46 19.05 18.68 18.6885 0.13689316
+ 20 18.51 18.63 18.59 18.5805 0.029285348
Difference at 99.5% confidence
-0.108 +/- 0.103894
-0.577895% +/- 0.552854%
(Student's t, pooled s = 0.0989883)
If you don’t know what ministat does, it just takes benchmark numbers
and runs statistical analyses. In this case, it is saying that at 99.5%
confidence, the statically-linked bc has 0.578% better performance.
To be honest, that is very little, especially since my bc can be sensitive
performance-wise. However, the standard deviation of the statically-linked
version is far better, so static linking probably will give more consistent
results.
Also, because of how my bc’s benchmark infrastructure is set up, we can
also compare RAM usage.
The -C option lets us choose which column of data we want, and my benchmark
script outputs max Resident Set Size (RSS) in column 4:
$ ./scripts/ministat -w78 -C4 -c99.5 ../bench1.txt ../bench2.txt
x ../bench1.txt
+ ../bench2.txt
+------------------------------------------------------------------------------+
| + x |
| + x |
| + x |
| + x |
| ++ x |
| ++ x |
|+++ x |
|+++ xxxx|
|+++ xxxx|
|+++ x xxxx|
||A| |AM||
+------------------------------------------------------------------------------+
N Min Max Median Avg Stddev
x 20 913172 913192 913188 913186 4.9417661
+ 20 912908 912916 912912 912912.4 2.8727394
Difference at 99.5% confidence
-273.6 +/- 4.2422
-0.029961% +/- 0.000464446%
(Student's t, pooled s = 4.04189)
It looks like there’s a big difference based on the graphic, but the difference is actually 0.0300%. That’s well within the margin of error, despite the claim of the confidence interval because RSS includes shared libraries, so in some sense, RSS counts memory against shared libraries that it should not.
A better measure would be Proportional Set Size.
New Ideas
I promised that I would give my ideas for software distribution. Here they are.
The Best Form for Software Distribution
First, in what form should we distribute software?
Surprisingly, the answer was (almost) in front of our nose for a decade and a half, in the form of LLVM, specifically its intermediate representation.
To start with, let’s take LLVM IR, or something like it, and assume that we can distribute software in that form. Can we?
Yes, with some conditions.
First, on every computer system that receives software in that form, there has to be a compiler that can take the IR as input and produce a native binary.
While this could be a problem, I don’t think it has to be because there are a lot of languages that have to use an interpreter to work, and users seem to be fine with installing such interpreters.
A compiler is just like those interpreters, so I don’t think installing one would be a burden on users.
Then, when installing software distributed that way, the compiler can be run on it to produce the final binary, and it does not have to do the full compilation; it just has to generate the final binary, like an assembler would.
Although, you could add machine-specific optimizations if you wanted to.
This makes the “recompile” (I’ll call it a “reassembly” from now on) cheap. I suspect it will be fast enough for most software that users will hardly notice.
This is all well and good, but what happens when one of the program’s static libraries are updated?
The answer: nothing. Which is fine.
However, if any of the program’s dynamic libraries are updated, it’s a trivial matter for the IR to be used to reassembly the program using the new dynamic library.
If the compile fails, then you know that there is an incompatibility with the API or ABI that must be fixed.
Likewise, if the compile succeeds, you know there were no problems or that they were solved by a reassembly.
You could distribute shared libraries like this too, allowing them to be easily reassembled if any of their dependencies change.
But we can do better. It’s possible to track updates to static libraries.
Most people install software through their package manager. If the package manager tracks the dependencies between static libraries and their dependents, the package manager could detect changes and run reassmblies as necessary.
If we wanted to go further, we could. We could add a mechanism to the OS to be
able to discover when the IR files for a library used by a program it launches
has changed. We could even have the OS start the compiler and have it exec()
into the new binary.
This would make sure that even libraries and programs installed by hand are properly updated.
Is the extra complexity in the OS worth it? I think it would be akin to an OS
supporting a #! line in scripts, with a little extra, but that extra
complexity still makes me nervous.
It’s not nearly as complex as a full dynamic linker, though, since it is just running a reassembly, and a dynamic linker is trying to do symbol versioning.
The coolest part about this idea, in my opinion, is that it allows users to explicitly decide which libraries are static and which are dynamic, but all libraries and their dependents are still properly updated.
It also takes into account the fact that most platforms require you to
dynamically link libc and works with that. Since libraries and programs are
reassembled whenever a dependency is updated, ABI and API breaks in the system
libraries becomes a non-issue.
In fact, it would be easy to detect what programs need to be reassembled because of updates to system libraries. That is one thing that dynamic libraries would do better in this case: they make it easier to detect dependencies on themselves.
This, in turn, means that updating the ABI of dynamic system libraries becomes easier and does not have to hold back a language or platform!
This is doubly great because it reduces the complexity of dynamic linking by removing the need for symbol versioning! This complexity reduction means that dynamic linking would actually become more feasible, making it more generally useful.
Platform-Independent IR
Unfortunately, using LLVM IR probably would not work, at least not directly. If you used it, you would need to distribute a different build for each platform.
However, we could design an IR that would allow us to include platform-specific code. If we did, then software could be distributed with the same IR for all platforms.
Gone would be the days of distributing different binaries for different platforms!
Machine-Specific Optimizations
If we could add code specific to certain platforms, we could probably also have code specifically for backends to use.
This vision comes from Daniel J. Bernstein’s talk called “The Death of Optimizing Compilers”.
Such code could include anything, but it would probably be most useful to have optimizations that users could have the backend run, using details about the actual hardware.
Preventing Stack Smashing
ASLR is meant to prevent exploits like return-oriented programming. This requires stack smashing. In fact, a lot of exploits require stack smashing.
This is because in order to get a program to execute code that an attacker controls, the attacker has to get the program to jump to his code.
Or, in the case of return-oriented programming, preexisting “gadgets” of code.
This is usually done by “smashing” the stack, specifically, overwriting the address that a function returns to, which is stored on the stack.
There are other ways to execute arbitrary code, but ASLR is specifically meant to defend against stack smashing, so that’s all I’m talking about here.
ASLR would be useless if we just prevented stack smashing in the first place. And it is easy to do that: just separate code from data.
You see, the stack is code. It has addresses to return to; that’s code. But the stack as currently implemented on all platforms that I know of also stores data.
That is the problem.
Well, it’s actually the fact that arrays can be stored on the stack. It’s only when programming languages allow accessing data on the stack as arrays. Without that, there is no buffer overflow, no stack smashing, and no need for ASLR.
So what if we had a heap-based stack where we stored all of the arrays that we would usually store on the stack? It could be pushed and popped, much like the actual stack, in order to allocate and deallocate memory. But it would not store any return addresses, and the stack would not store any arrays.
With the two separated, stack smashing becomes impossible, and ASLR becomes useless.
Now, I don’t blame Ulrich Drepper for not seeing this in 2006. In fact, even the OpenBSD guys, famous for being anal about security and the first to deploy ASLR by default (so they claim), got this wrong! We all got this wrong!
Well, except for the few who have already done it. I’m sure there are some.
By the way, I believe that ASLR is, itself, a problem. It adds complexity to our software stack, and complexity breeds insecurity.
It’s so important, I’ve now said it three times! And there are three links there.
As such, I believe ASLR is itself a vulnerability waiting to happen.
And of course, once ASLR is useless, not only is the complexity of static PIE useless, but another argument against static linking and for dynamic linking is down.
Statically Mapping Libraries
Once we have prevented stack smashing with separate code and data stacks, and also reassemble libraries and programs when their dependencies are updated, there is actually something else we can do, something that would give us the efficient memory use of dynamic libraries with the overhead of static libraries.
Operating systems can statically map libraries.
Say you have a library used by many programs, like libcurl. You, as a user,
could tell your OS to always map it into the same place in virtual memory.
Then, whenever a program needs it, the program knows that it is always going to be mapped at that location and does not need to have an extra jump table for jumping to code in the statically-mapped library. This would eliminate extra function call overhead and the need for running a runtime linker before the program.
The reason we don’t do this now is two-fold:
- First, statically mapping libraries would make it easier to run Return-Oriented Programming attacks because attackers can more easily figure out where system libraries are mapped.
- If the statically-mapped library gets updated, its static mapping could be changed because the new version might need more space than the mapping gives it. Then its dependents wouldn’t know where to find it and would experience problems.
These two problems are solved by separating code and data stacks and by reassembling dependents.
Conclusion
After reading this post, I hope you don’t think that there is no place for dynamic linking in this world. This is wrong because sometimes, it is still better to dynamically link.
As Linus Torvalds said:
[S]hared libraries…make sense…for truly standardized system libraries that are everywhere, and are part of the base distro….Or, for those very rare programs that end up dynamically loading rare modules at run-time - not at startup - because that’s their extension model.
This is why my redesign allows for dynamic linking of system libraries and why
dlopen() will never go away. This is okay. It’s even desirable.
That’s not the problem.
The problem is that we bias towards dynamic linking when we should bias towards static linking.
That’s it. That’s the conclusion and the tl;dr:
We bias towards dynamic linking when we should bias towards static linking.
They both should be easy, but static linking should be easier, and it’s what we should always start by doing.
And of course, we should not just stick with what we already do.
So let’s try some new ideas!