Assumed Audience: Hackers and suits in the tech industry.
Discuss on Hacker News.
Epistemic Status: Confident.
The Introduction
So I saw a post today, and it’s so wrong I was about to post a ranty missive on Hacker News.
But my ranty missives get long, so here’s a blog post instead.
tl;dr: Code is an asset, and tech debt is when the software and its internal model do not match the problem and the mental model, or when the internal interfaces do not minimize assumptions.
The Post
The post is “All Code Is Technical Debt” written by Paul McMahon.
And everything is just slightly wrong, starting from the title.
So let’s break it down.
The Thesis
Paul’s thesis is at the end of his introduction:
As the more code you add to an application, the slower development becomes, I view all code as technical debt.
But is this true? Does development speed always get slower if you add code?
Let’s look at the corollary: does development speed always get faster if you remove code?
That is false on its face!
One of the reasons people don’t like C (besides memory bugs) is its paltry standard library! C is basically the extreme of “remove code,” and I can tell you from experience that its tiny standard library slows development.
I’ve spent about 7 years building my own C libraries as a replacement.
So if the corollary is not true, is the thesis?
It is absolutely not true.
Take this commit from my most famous project.
In that commit, I am adding three, three!, new keywords and commands to bc
and dc.
For that commit, I deleted 7 lines and added 108.
More accurately, I changed 7 lines and added 101.
That means I deleted an average of 1 line per keyword per program, and added an average of 18 lines per keyword per program.
Okay, let’s see how much of that code exists 537 commits later.
To get the 537 number, I ran git rev-list 1ead5b96..HEAD | wc -l.
I ran blames and took out whitespace-only code style fixes. Of the 108 lines, 77 still exist. That’s 71.2%.
And most of the ones that changed were numbers or other data that got changed when I added other keywords.
But the other key is how easy it was to add those features; even if we count both programs together, adding a keyword took me 36 lines. That’s easy to review, easy to test, and easy to change. It’s like technical debt does not exist.
And that is intentional.
“Okay, Gavin, but what does that have to do with Paul’s thesis?”
Paul’s point is that adding code is always more technical debt. He said,
When you’re first building out an application, you can develop new features at incredible speed. There’s no need to worry about the impact on existing users. You can just focus on implementing new features.
However, as an application matures, development speed will inevitably slow down. On a poorly implemented product, development speed slows down quickly. But even on a beautifully implemented one, development speed still slows down over time.
But that was not the case for these three features. They took me about two hours total, including testing!
This was not the case when I started; I could take weeks to add just one new feature!
So my development speed has increased even though my code has grown!
How much has it grown? This much:
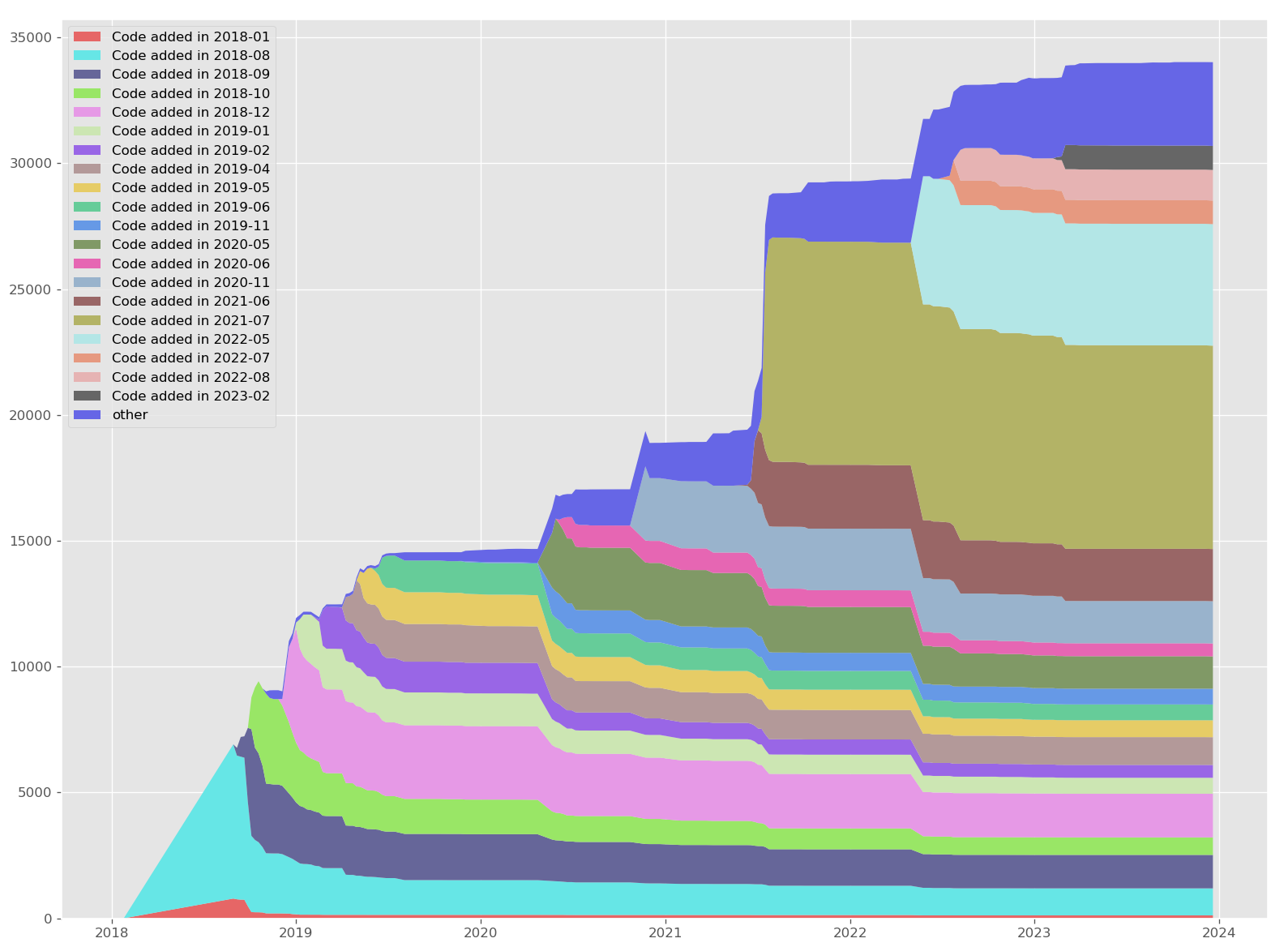
And that image only counts files in include/, src/, and gen/. It also
excludes text files in gen/.
In particular, note that the only month that lost a significant amount of code is Aug 2018, which was early.
If you were to plot the survival rates of code in bc, it would look like this:
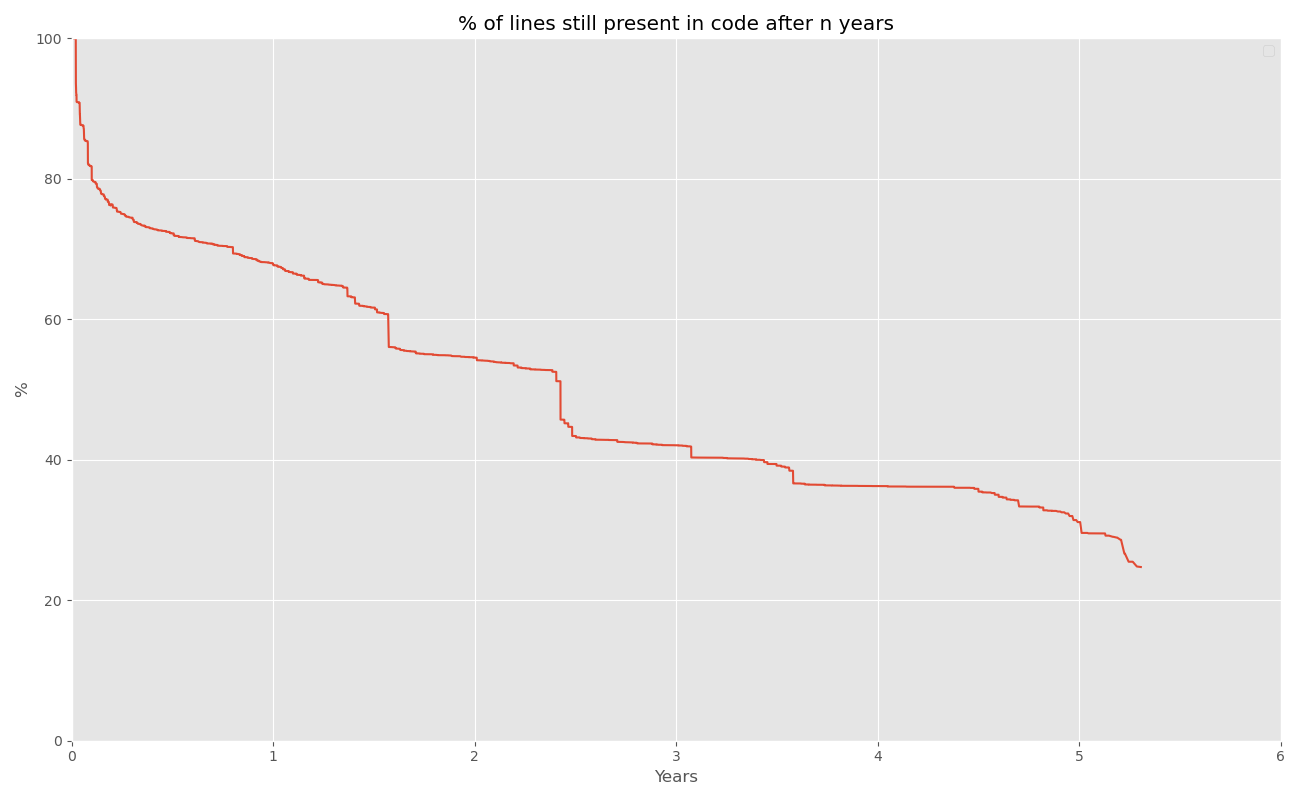
And again, that only counts files in the same directories as above. If you plot the survival rate for the entire repo, you’ll get this:
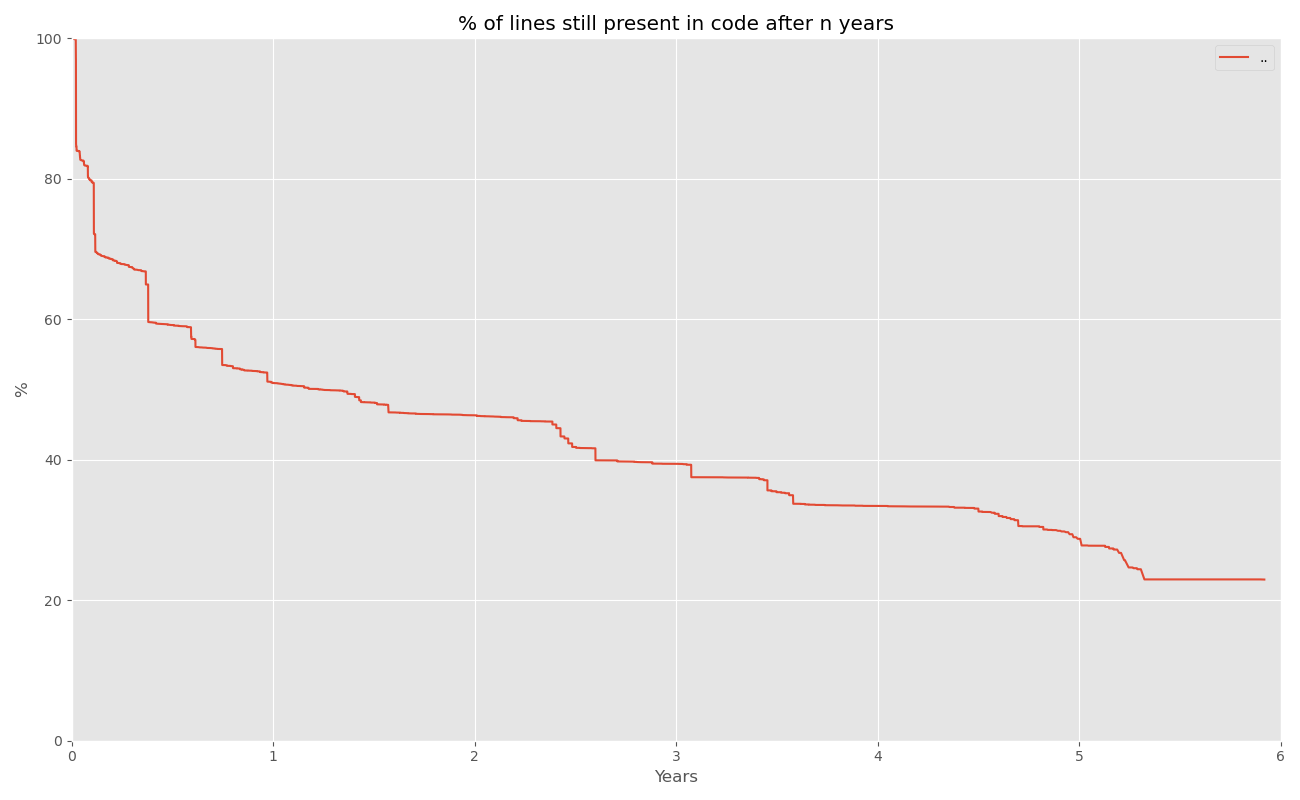
Notice that the first 40% disappeared in six months, but the next 40% is still not gone more than five years later.
Also, do you see those small cliffs at various points? Those are where I did a refactor to reduce tech debt.
There was a large cliff at the beginning because I was exploring and refactoring as I went. I finally settled into something good after six months, but I didn’t rest on my laurels; when I saw a problem, I fixed it.
In fact, I often added code to reduce tech debt.
An example is when I implemented my own file I/O in bc.
“Oh, Gavin…”

No I’m not.
You see, I have a built-in command-line history implementation, and that needs raw access to the terminal for obvious reasons.
If I used the regular file I/O, it would have “worked,” but I would deal with sticky issues between it and history.
But by implementing my own, I got rid of the sticky issues and reduced my tech debt.
Adding code reduced my tech debt.
Paul is right by rule of thumb, but I would rather not be ruled by thumbs.
So let’s find a more precise “rule.”
The Rule
I already came up with one:
Your software is trying to solve a problem, and every problem has an unknown shape because reality has a surprising amount of detail…
Technical debt is every place where the software does not fit the problem.
(Emphasis added.)
And it is that simple: tech debt is when your software (and the model behind it) do not fit the problem it is trying to solve.
Well, not quite…
The Metaphor
“Okay, Gavin, so what about our metaphor? Should we want more code or less? Because it sure sounds like you’re advocating for more code.”
Nah, less code is better, all else being equal. But “all else equal” is lottery-rare.
That’s not to say that “less code equals better” is also rare; it’s not.
I would like to propose a different metaphor: code/software is an asset.
“Well, what’s tech debt, then?”
Patience.
If I’m going to go all in on financial terms, let’s add liabilities:
- Liability
The quantity of value that a[n]…entity owes.
As a programmer, you owe the ability to solve a problem. Anything in the code that doesn’t solve the problem is part of that liability.
So technical debt is really code liability.
I use the term “code liability” not “tech liability” to emphasize that it is not just a problem for techies.
“That’s stupid, Gavin; assets can’t be liabilities, so your metaphor is wrong.”
True, assets cannot be liabilities, but they can have liabilities attached to them.
For example, say I buy a car with financing; that debt is a liability even though the car itself is an asset, and that liability is attached to the car.
In like manner, code as an asset can have a liability attached that lessens the value of the asset.
It goes further: you can be “underwater” on an asset. This means that your asset may be worth less than the liability attached to it.
You can experience this with code as well; when development slows to a crawl, you’ve gone under.
It can happen in two ways: the problem changes (your liability increases) or your software becomes less useful (your asset depreciates).
Yep, I’m still going on the financial metaphors.
“How can software depreciate, Gavin? It’s just code.”
node_modules enters the chat
If its environment changes, it may not run. And software that won’t run has depreciated to nothing.
This is another reason I choose C: the environment does not change.
“But that doesn’t explain your supposed ‘zero’ code liability, Gavin.”
You’re partially right. I do keep up to date on the problem, and I do update my software to fit the problem.
The Interfaces
But that is not the only reason I have nigh nil code liability and why you do not.
Paul says, “Adding new assumptions increases debt,” and in this, he is correct.
But he is assuming that adding features requires adding assumptions. If you create and use interfaces properly, few to no new assumptions are necessary.
Don’t believe me?
Remember that I added keywords to my bc; all three needed zero additional
assumptions.
The parsing followed the existing assumptions of the parser (parse up to the character you need and no more) and the existing assumption of the virtual machine (remove operands from the results stack and replace them with the result).
“But that’s just because you were making a programming language and could make easy assumptions!”
Uh, this programming language is Turing-complete! That is the very definition of hard in programming. It’s also hard to making a programming language match the problem it is made to solve.
And I have pulled off the same thing in a larger language with user-defined keywords and user-defined lexers!
Coming soon…
To wit: your interfaces should minimize assumptions.
Or in other words, the code’s internal model (assumptions) needs to match the internal interfaces.
I do this by:
- Never programming past my limited ability.
- Strictly documenting interfaces, including preconditions and postconditions.
- Strictly programming to those interfaces, adjusting one or the other as necessary.
- Iterating until the interfaces are close to perfect.
I know I have succeeded when those interfaces make it easy to add stuff without intefering with other features.
The Model
And yet, that is still not enough.
The last way software can have a liability is that it doesn’t match the model.
The mental model.
“Programming as Theory Building” (original) is a famous essay (which you should go read right now!) that uses the word theory for this concept, but it is the same concept.
Whatever the term, the model/theory is the software as it exists in the minds of those who create and use it.
Of course, the mental model will be inaccurate; if it wasn’t, we would never have bugs, so the other form of code liability is when the software is different from the mental model.
I fix this by testing, testing, testing. I fuzz with a crash-happy build, and I fix every bug.
“But how does that improve your mental model?”
Because for me, one of the definitions of a bug is a mismatch between my mental model and the reality of the software.
So when I fix a bug, I’m bring my model and the reality closer together. And I do this until they are in harmony.
Sometimes, this includes changing my mental model when the reality is better.
The Bloat
In addition, unneeded bloat is also code liability.
All code has a cost because assets have to be maintained, so extra code will have a higher maintenance cost than necessary.
I regularly look for code to purge.
The Prevention
I also do one more thing that almost no developer does: I actually design my code before I ever start coding.
In other words, I build a mental model, including the problem that the software solves, before I start.
This keeps my coding laser-focused on its purpose and helps me prevent divergence between reality and model.
Of course, I do have to update the initial model, but an ounce of prevention is worth a pound of cure.
And that is how I smash code liability.
The Other Points
I guess I should respond to Paul’s other points.
Yes, that is true, and that matches with my metaphor.
A feature that does not match the problem has negative value, but it is still an asset, just a bad one, like a junker car.
In the real world, assets can also be a poor match for their purpose, such as the Airbus A380.
Yes, that is true.
Code that does not match the problem has negative value.
You heard that right: this is just a restatement of of “Features can have negative value.”
This is also mostly true.
This is why I’m bullish on keeping code liability to a minimum from the start; if I ruthlessly prune features before they can entrench themselves, this terrible fact is not a fact for me.
I suggest you do the same if you can while still meeting your business goals.
Well, yes, but this is also like saying “to avoid missing in basketball, don’t shoot.”
Code is an asset, but you need assets to do stuff.
Just remember that assets need maintenance to remain above water. Write code to solve problems, and make sure that code matches the problem. Maintain it to keep it that way.
Yes, this is great advice; it is the same advice I gave above about assumptions, although you should change bad assumptions if you can.
The Conclusion
Tech debt and code liability are hotly debated, so let me throw out my opinion:
- Code is an asset.
- Code can have a liability attached, which can be one or more of:
- When the code does not match the problem.
- When the code’s internal model does not match the problem.
- When the code’s internal model does not match the mental model of users and programmers.
- When the code’s internal model does not match the code’s internal interfaces.
- And yes, when there is more code than necessary to match the problem.
- You can be underwater on code; this is when development stalls.
- Thus, code must be maintained, just like any other asset.
Am I right? Well, I’ll leave that for you to decide.
Edit (2023-12-21): Added “The Bloat” section based on Hacker News comments.